Measuring meaning composition in the human brain with composition scores from large language models
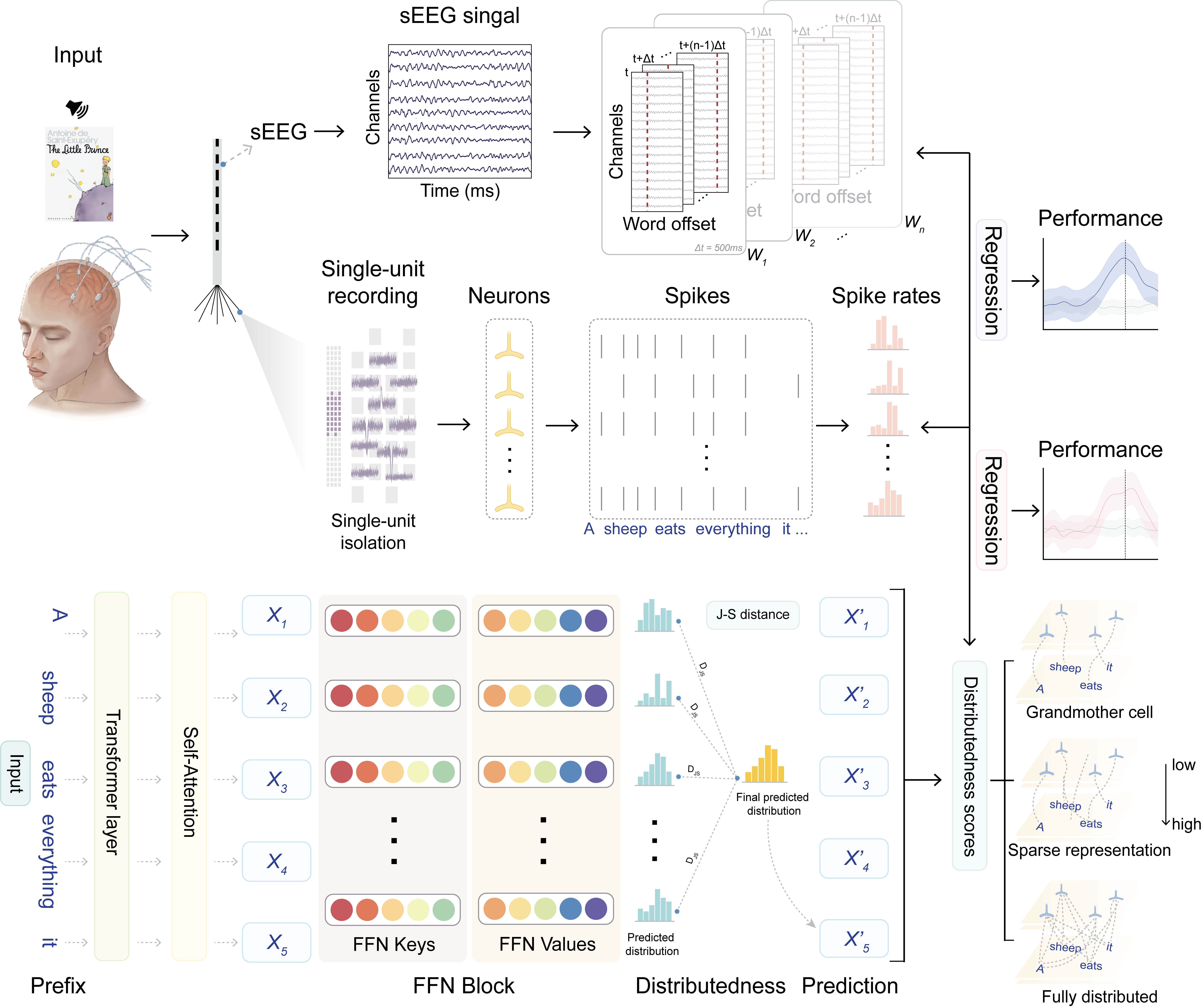
The process of meaning composition, wherein smaller units like morphemes or words combine to form the meaning of phrases and sentences, is essential for human sentence comprehension. Despite extensive neurolinguistic research into the brain regions involved in meaning composition, a computational metric to quantify the extent of composition is still lacking. Drawing on the key-value memory interpretation of transformer feed-forward network blocks, we introduce the Composition Score, a novel model-based metric designed to quantify the degree of meaning composition during sentence comprehension. Experimental findings show that this metric correlates with brain clusters associated with word frequency, structural processing, and general sensitivity to words, suggesting the multifaceted nature of meaning composition during human sentence comprehension.
Functional specificity in multimodal large language models and the human brain
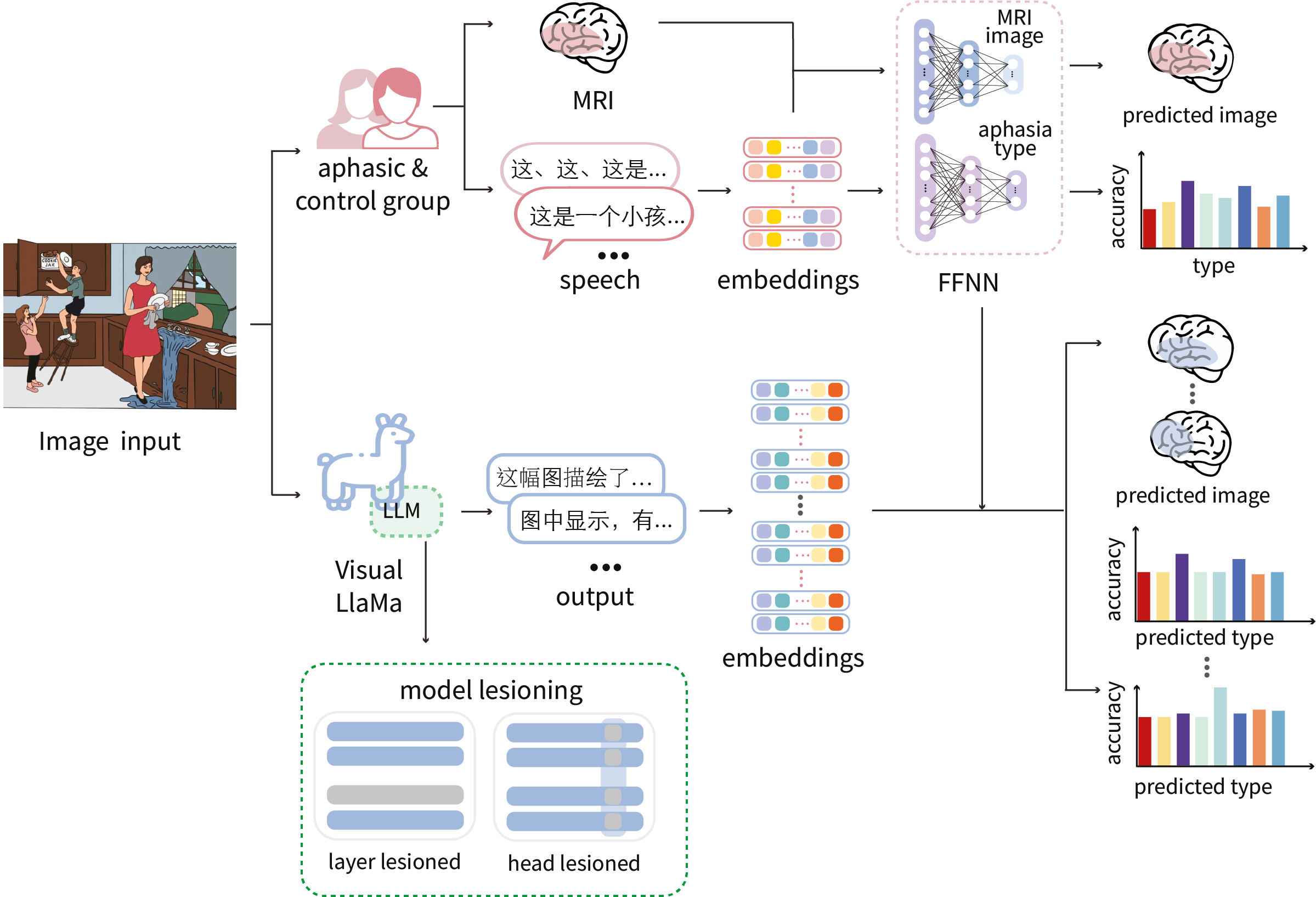
Recent large language models (LLMs) have demonstrated impressive performance across a wide range of natural language processing (NLP) tasks and are believed to share computational similarities with the human brain (e.g., Goldstein et al., 2022). However, concerns persist about using one “black box” (LLMs) to model another (the human brain), emphasizing the need for increased transparency in LLMs. This study investigates the functional specificity of multimodal LLMs and their parallels to the human brain by simulating language deficits observed in aphasia. By selectively lesioning components of the model, we aim to replicate symptoms such as motor and sensory deficits and compare the model’s output to real-world patient data. This approach enables the exploration of linguistic subprocesses within LLMs, offering insights into how the brain’s language networks process and distribute linguistic function.
Modeling multi-talker speech comprehension in normal and hearing-impaired listeners
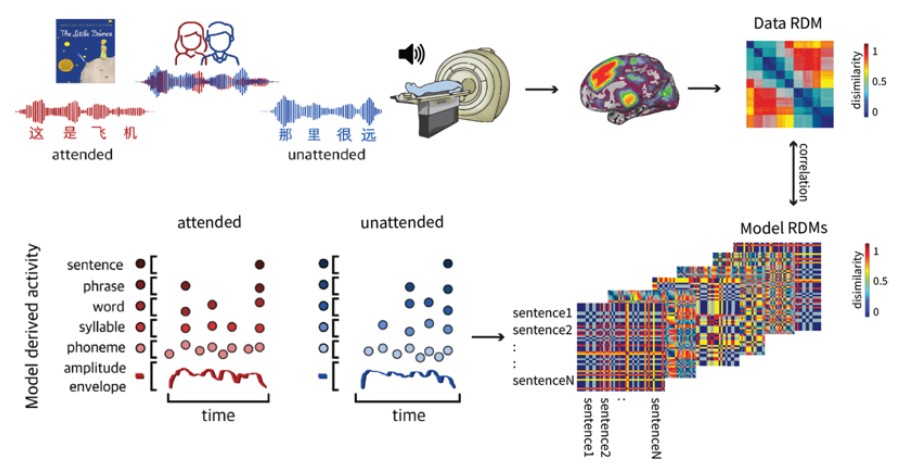
Speech comprehension involves understanding a hierarchy of linguistic units from phonemes up to narratives. Prior studies suggested that the neural encoding of different linguistic units follows a hierarchy of increasing temporal receptive windows from lower-level sensory brain regions to higher-level perceptual and cognitive areas (Hasson et al., 2008; Honey et al., 2012; Lerner et al., 2011; Murray et al., 2014). Yet how the linguistic units of multi-talker speech are represented in the brain remains elusive. Specifying the neural underpinnings of different linguistic units in competing speech streams is essential for understanding speech comprehension in adverse listening conditions, and is the first step toward a biomarker for hidden hearing loss, which has become increasingly common in young adults (Motlagh Zadeh et al., 2019).
Modeling associative encoding of speech sounds in rat and human auditory cortex
Associative memory comprises linking together component parts (e.g., sounds and meaning) either directly or via spatial, temporal or other kinds of relationships. The idea of associative encoding is at the core of distributional semantics, which states that words occurring together are usually semantically related. Prior studies on associative memory encodings have localized the medial temporal lobes for associative recall in both the animal and human brain, yet fine-grained mechanistic models of the associating process are still lacking. The proposed study exposes both rats and human adults to sequences of vowel sounds varying in lexical tones during electroencephalogram (EEG) recording. We then test whether the co-occurring statistics of two consecutive tones during exposure facilitate tone pairings using a two-choice auditory task. We leverage recent deep-learning techniques to model the processes of associating two tones together in the rat and human auditory cortex.
Le Petit Prince multilingual naturalistic fMRI corpus
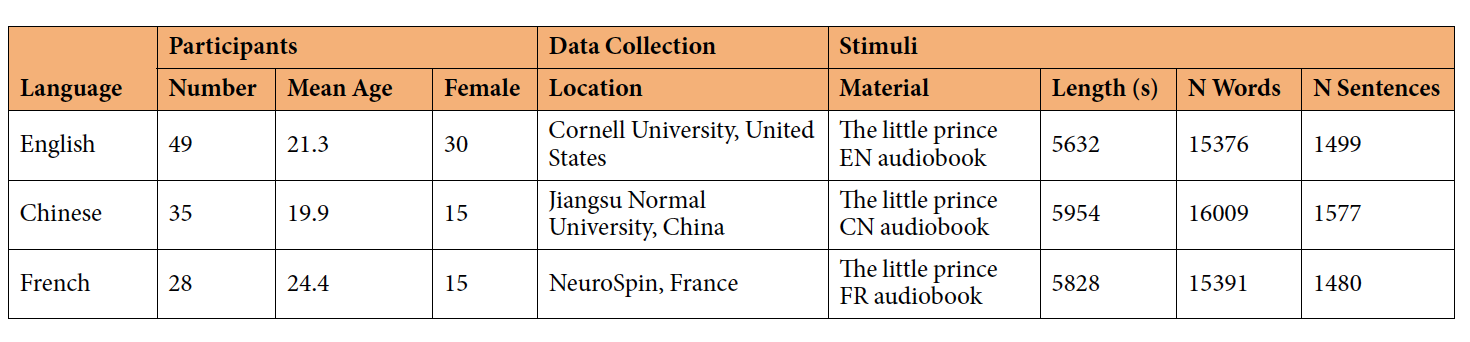
Neuroimaging using more ecologically valid stimuli such as audiobooks has advanced our understanding of natural language comprehension in the brain. However, prior naturalistic stimuli have typically been restricted to a single language, which limited generalizability beyond small typological domains. Here we present the Le Petit Prince fMRI Corpus (LPPC–fMRI), a multilingual resource for research in the cognitive neuroscience of speech and language during naturalistic listening (OpenNeuro: ds003643). 49 English speakers, 35 Chinese speakers and 28 French speakers listened to the same audiobook The Little Prince in their native language while multi-echo functional magnetic resonance imaging was acquired. We also provide time-aligned speech annotation and word-by-word predictors obtained using natural language processing tools. The resulting timeseries data are shown to be of high quality with good temporal signal-to-noise ratio and high inter-subject correlation. Data-driven functional analyses provide further evidence of data quality. This annotated, multilingual fMRI dataset facilitates future re-analysis that addresses cross-linguistic commonalities and differences in the neural substrate of language processing on multiple perceptual and linguistic levels.